Erkennen einer Sprache ohne Wörterbuch - ein einfaches Beispiel der N-gramme-Methode
Einem Text anzusehen, in welcher Sprache (außer den meistverbreiteten) er geschrieben ist, ohne dazu in Wörterbüchern nachzuschlagen – ist das überhaupt möglich? Die Computerlinguistik kennt eine anschauliche und einfache Methode, mit der dies gelingen kann.
Ein Mensch kann oft bereits anhand von wenigen Sätzen und ohne Zuhilfenahme eines Wörterbuchs erkennen, in welcher Sprache ein Text geschrieben ist. Die Buchstaben und Symbole verraten, welchem Sprachraum – z.B. dem westeuropäischen, griechischen, russischen, indischen oder asiatischen – der Text angehört. Indizien für eine weitere Eingrenzung sind diakritische Zeichen wie „é, è, ê, Ł, ň“ und Satzzeichen wie „!, ?,¿, ؟, ᠃, ፣“.
Ein Computer geht anders vor. Er braucht zwar auch kein Wörterbuch, aber ihm sind ein Alphabet und die Bedeutung eines Einzelzeichens egal. Er zählt in sehr vielen Trainingsdaten aus verschiedensten Domänen einfach die Vorkommen jedes Zeichens für die einzelnen Sprachen oder sogar Dialekten, errechnet verschiedenartige Anteilswerte und legt diese Statistik als eine Art Fingerabdruck ab. Im Deutschen gibt es z.B. sehr viele „e, n“ und wenige „y, x, q“; im Englischen sind es „e, t, a“ bzw. „x, q, z“. Weitere Merkmale wie die Anteile von Groß- und Kleinbuchstaben, Leerzeichen, Satzzeichen und die Verteilungskurve von Satz- und Wortlängen verfeinern den sprachlichen Fingerabdruck. Für die Sprachenerkennung wird vom unbekannten Text auch ein Fingerabdruck errechnet und mit den vorhandenen verglichen. Die größte Übereinstimmung zeigt die gesuchte Sprache.
Aber der Computer betrachtet nicht nur Einzelzeichen (Unigramme), sondern auch zwei benachbarte Zeichen (Bigramme), egal ob es Alphabet-Zeichen, Leerzeichen oder Satzzeichen sind. Dabei wird mit überlappenden Bigrammen gearbeitet, d.h. das erste Bigramm beginnt auf Position 1 und enthält das erste und das zweite Zeichen, das zweite Bigramm beginnt auf Position 2 und enthält das zweite und das dritte Zeichen usw.
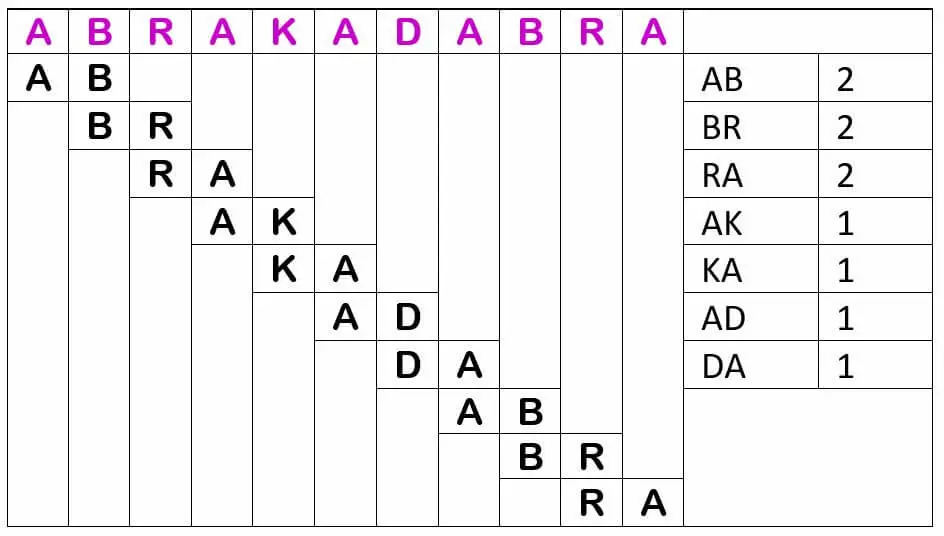
Wieder finden sich je nach Sprache typische häufigere Kombinationen, besonders bei Wortpräfixen und –suffixen. Im Deutschen sind dies „er, en, el, be, ge, ab, an, zu, st, kl, kr, br, pr, kr, bl, ei, ch, ig“, im Englischen „un, in, il, im, ir, re, ex, or“. Weitere Informationen liefern die Trigramme; im Deutschen sind dies „sch, str, ver, auf, aus, bei, ein, ent, her, hin, vor, zer, ung, nis, tum, tät, gen, ben, hen, sen, kel, pel, kel, der, ter, ber, ler, sam, bar“, im Englischen „dis, non, mis, ian, ism, ive, sis“. Als nächstes kämen die 4-Gramme usw. Je präziser der Fingerabdruck einer Sprache, um so leichter lassen sich eng verwandte Sprachen unterscheiden.
Da die Methode der N-Gramme unabhängig von Sprache und Alphabet ist, wird sie auch bei der Entschlüsselung von Geheimschriften angewendet. Außerdem ist sie gut dafür geeignet, schnell und einfach eine Aussage über den Inhalt eines Textes machen zu können. Dabei bildet man die N-Gramme nicht auf Zeichen-Ebene, sondern auf Wort-Ebene. Die Referenz ist hier ein konstruierter Text, der alle Schlüsselwörter und –ausdrücke sowie besonders alle Umschreibungen zu einem gewünschten und vordefinierten Thema enthält, und dadurch eine „ideale“ Fingerabdruck-Statistik liefert. Im Abgleich damit lassen sich z.B. E-Mails oder Foren-Beträge mit „gefährlichen“ Inhalten zum Thema Terrorismus oder Drogenanbau finden.
Die Spracherkennung ist in unserer globalisierten Welt sehr wichtig geworden. Sie wird z.B. bei Webinhalten und multinationalen Archiven eingesetzt.

Informatikerin und Computer-Linguistin
Ulrike ist Informatikerin und Computer-Linguistin. Der thematische Schwerpunkt ihrer Blog-Beiträge zielt auf die Verständlichkeit und Bedienbarkeit des Mensch-Maschine-Interface.
Weitere Artikel von Content in Context

|
|

|
|
|
|